Predicting patient drug experience with deep learning
Sentiment analysis over online medication reviews — neural networks turn unstructured patient text into satisfaction scores at research-grade accuracy.
For our course Advanced Machine Learning for Public Policy, my team undertook a sentiment analysis project using the various Natural Language Processing (NLP) and Deep Learning concepts learned throughout the academic term. Building upon the data obtained by Grasser et al (2018) — online drug reviews scraped from Drugs.com — we extended the dataset by writing a scraper to pick up where the data leaves off, pushing coverage through May 2021.
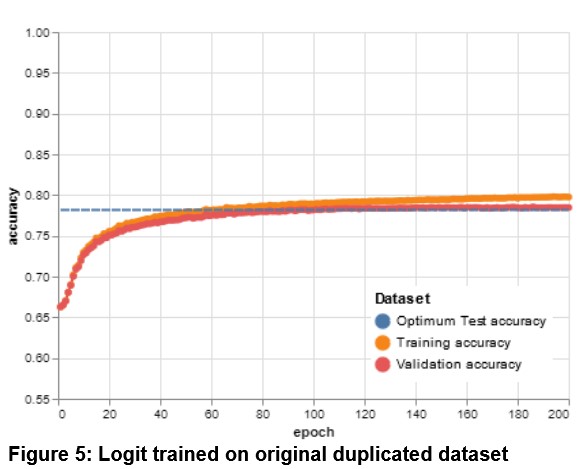
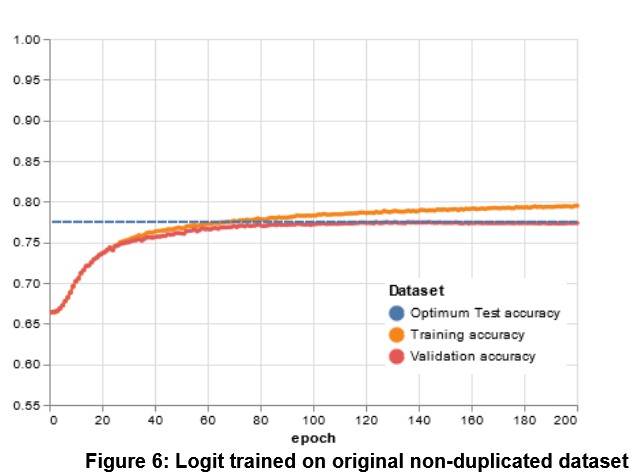
While scraping the website and updating the dataset, we noticed that a large number of reviews in the original dataset were duplicated (40%, more precisely) and we explored the implications of these duplicates on the models in previously published research articles. We trained a Logistic Regression (as used by Grasser et al) with both the duplicated and unduplicated datasets (see Figures 5 and 6 below), as well as the results from an LSTM model with both datasets. We found little difference in accuracy for the Logistic Regression — however, the LSTM performed at a 10% higher accuracy on the dataset with duplicates.
Code repository can be found at this link.
Return to main